dgiot云压测
简述
dgiot云测平台,面向物联网各种垂直领域的全业务云端检测平台,内部集成可视化任务模块、压测指标分析模块、自动压测报告模块等。 支持物联网企业在线创建各种业务场景任务、性能执行脚本、实时监控任务执行过程中性能指标,并自动输出专业的全业务测试评估报告。
dgiot云压测特点
轻 多种操作系统平台;30分钟可部署调试
快 一键式快速部署;压测任务可视化配置
省 只花费传统费用1/5,即可享受运营级服务器压测专业服务
专 团队专注高并发服务器研发7年以上,运营过亿级商业平台
dgiot云压测主要步骤
- 构建插件模拟海量设备注册,数据上报,数据存储、数据消费的全业务场景
- 构建符合Promethus规范exporter指标体系实时监控全业务链路上各项指标
- 构建Grafana可视化面板,实时呈现各项指标在整个压测过程中变化趋势
- 构建专业的压测报告,通过专业的AI算法做自动化的技术判定
用户痛点
开发用户痛点
- 网络制式多
物联网的的网络制式,根据需求不同,有如下类型: NB-IoT/ZETA/ZETag/Lora/LoraWan/Wifi/2/3/4/5G/蓝牙/ZigBee - 协议种类多 网络的协议类型,较互联网碎片化严重,存在大量私有协议类型,导致接入调试的工作量非常繁琐
- 产业链条长 产业的联调,从各种类型的传感器、网关、基站、物联网平台、时序数据库、大数据展现平台等,每个环节都必须需要联调与大量的连通性测试、安全性测试、压力测试、业务模拟测试等工作
- 业务复杂 物联网几乎覆盖所有的行业,所以各个领域都有自己的业务类型和流程,对接的第三方平台也非常多,各种对接和适配,都需要繁重的测试工作
平台运维用户痛点
- 运营质量无法预测 传统的监控工具只能监控基础资源,无法透视业务质量,当设备数量和种类增加时,无法预测平台的服务质量,只有出现问题后,临时被动应对。无法评估平台的未来承载和服务能力
- 协议多模拟难 物联网特有的传感器种类繁多,网络制式多样化,协议种类众多,模拟各种业务场景非常困难,解决相关问题,所需的专业背景知识深厚,专业门槛较高
- 协调困难 出现运营故障,急需救火,各部门需协调,排查效率低,难以确认根源及责任部门,故恢复时间长
- 验证成本高 服务器需长期跟踪,业务变化因素多,设备种类多,导致验证成功很高,急需专业工具和平台
产品功能
一站式全业务压测功能
压测任务可视化配置
一键克隆:系统提供一键克隆功能,专门应对任务数量多,重复信息大的情况,极大减轻任务信息录入工作量
任务时间设置:任务开始时间与结束时间可自动设置,也可手动启动和停止,满足顾客多样性需求
可视化操作:提高可操作性和准确度
服务器运行实时展示
组态实时展示 进程信息,CPU信息,负载内存等服务器运行状态
保障服务器运行稳定性和有效性
自动化压测报告生成
压测报告自动生成:任务完成后即可自动生成压测报告,省去人工填写与查错,极大节省了人工,提高了效率和准确度,特别适合大量输出压测报告的场景
适配性高:报告模板可选择,提高适配性。也可上传新的模板,通过“贴值”使其可通用于任意报告
数据分析和数据计算扩展
物模型解决数据采集和数据存储定制化需求
扩展API解决数据分析和数据计算定制化需求
动态报告系统解决数据呈现定制化需求
权限系统和用户系统解决数据安全的定制化需求
全面的服务器指标统计
针对服务器的全方位灵活的统计指标特点:
易于管理、可扩展、易集成
轻易获取服务内部状态
高效灵活的查询语言
支持本地和远程存储
采用http协议,默认pull模式拉取数据,也可以通过中间网关push数据
支持自动发现
服务器性能统计指标如下
系统CPU使用情况
磁盘I/O
文件系统使用量
系统负载
系统内存使用量
TCP
网络宽带
多维度的系统监控与报警
系统监控和警报系统特色:
多维度数据模型-由指标键值对标识的时间序列数据组成
不依赖分布式存储; 单个服务器节点是自治的
以HTTP方式,通过pull模式拉取时间序列数据
支持通过中间网关推送时间序列数据
通过服务发现或者静态配置,来发现目标服务对象
支持多种多样的图表和界面展示
系统异常及告警设置如下:
根据历史监控数据,对为了做出预测
发生异常时,即使报警,或做出相应措施
根据监控报警及时定位问题根源
通过可视化图表展示,便于直观获取信息
通过多种途径通知告警,如邮件、短信、社交工具等
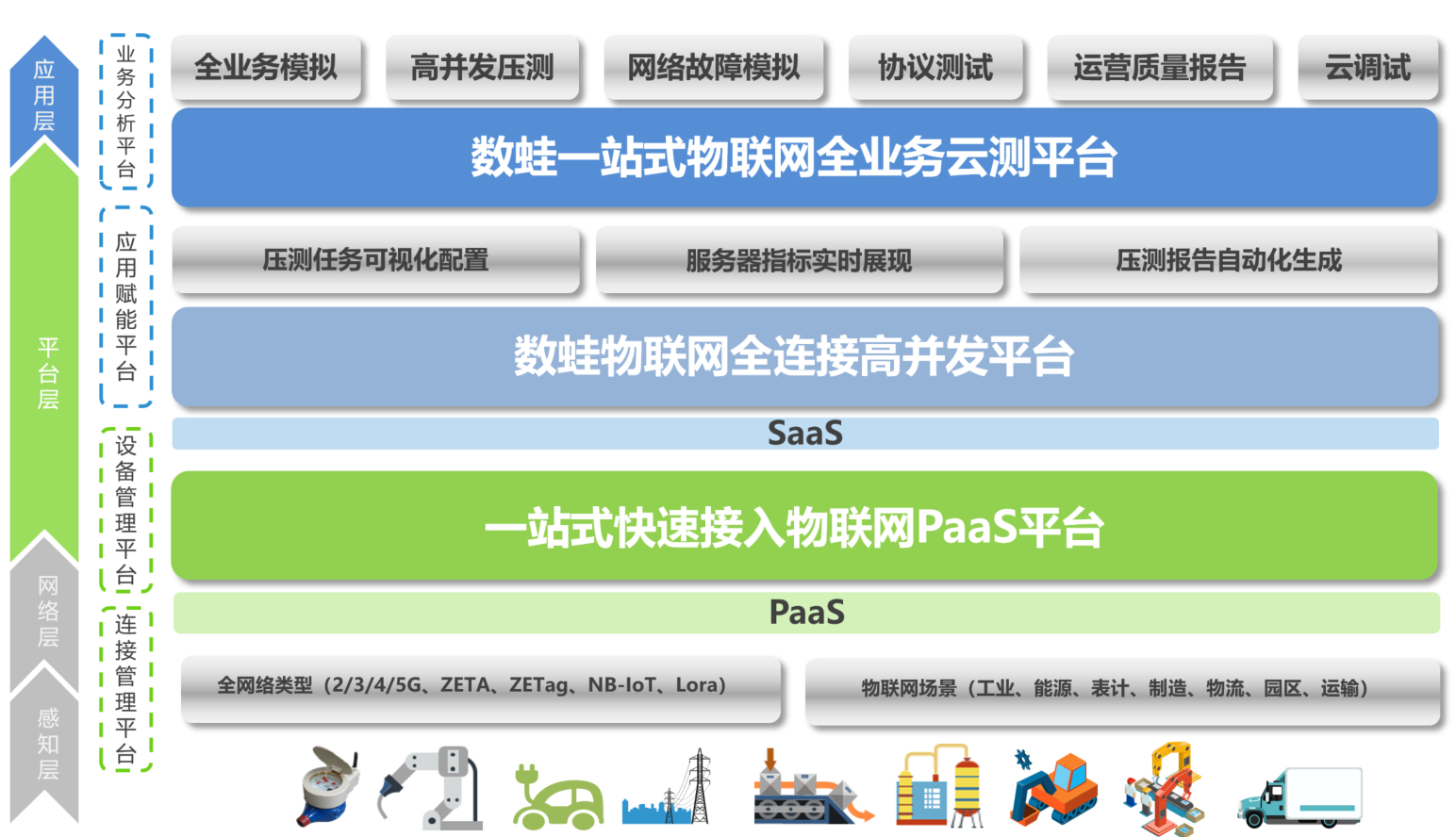
产品架构
云压测
dgiot云压测产品是基于dgiot物业物联网平台的一款云计算产品,可以模拟真实业务场景进行全业务场景模拟和全链路数据监控
产品优势
平台优势
物联网全业务测试
- 全场景测试:采集、传输、解析、存储、展现
- 全链路测试:传感器、网关、网络、服务器、数据库
- 全性能测试:数百种服务器、网络、数据库、传感器的统计指标
专业级云测平台
- 海量终端模拟
- 动态多场景、多任务压测
- 可承载千万级设备、百亿级数据
- 支持私有化部署与业务对接
- 支持集群与动态扩展
- 物模型、规则引擎可视化配置
- 提供专家指导测试服务
兼容国际主流制式
- 网络类型:NB-IoT、Lora、ZETA、ZETag、2/3/4/5G
- 网络协议:TCP/UDP、HTTP/S、MQTT、CoAP
- 各种PLC设备协议,如Modbus等
- 各种表计协议,如DL/T645、DLMS等
- 数据库:MySQL、Postgres、TDengine、MongoDB、SQL Server、Redis、ACCESS
全业务模拟压测
- 可模拟平台满负荷全业务运行场景
- 可模拟设备:表计、网关、路由器等
- 可模拟各种行业场景(电力、车联网、物流、工业管控、能源管理、智慧城市、智能家居)
应用场景
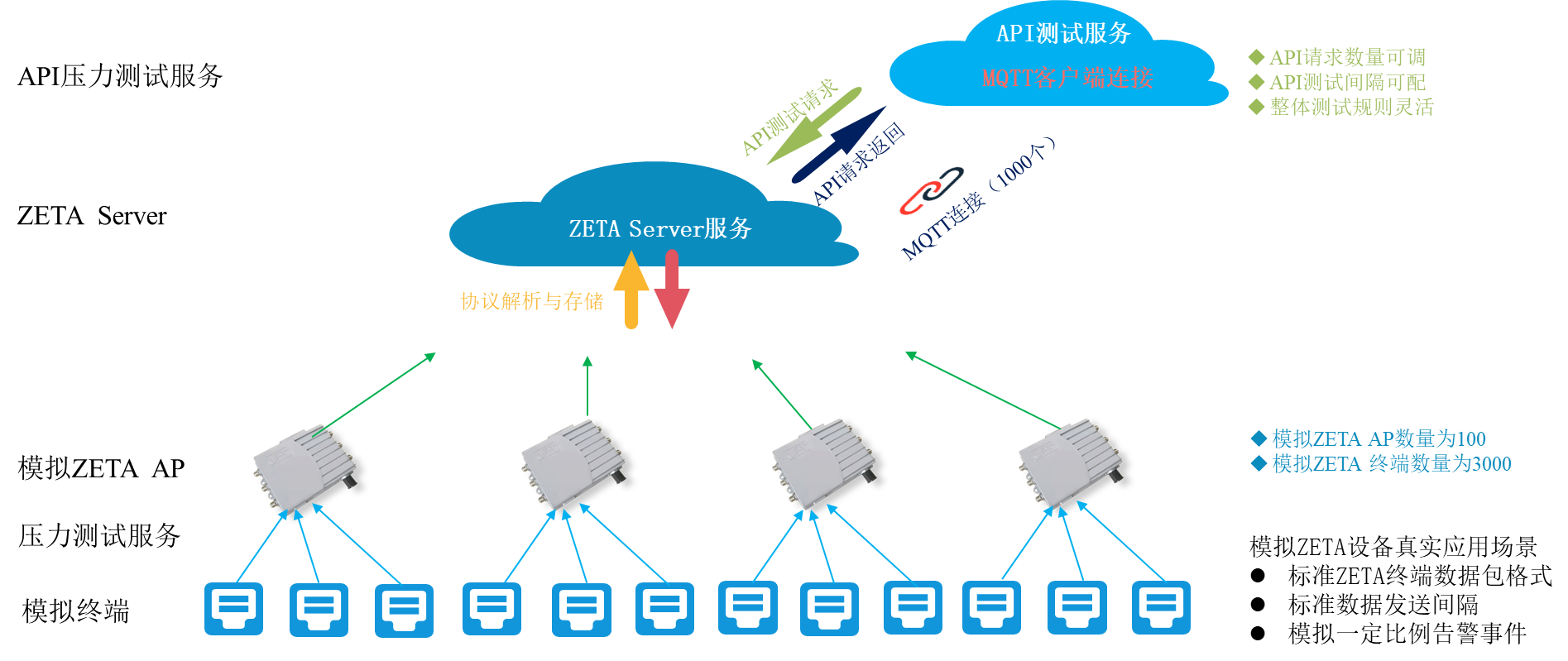
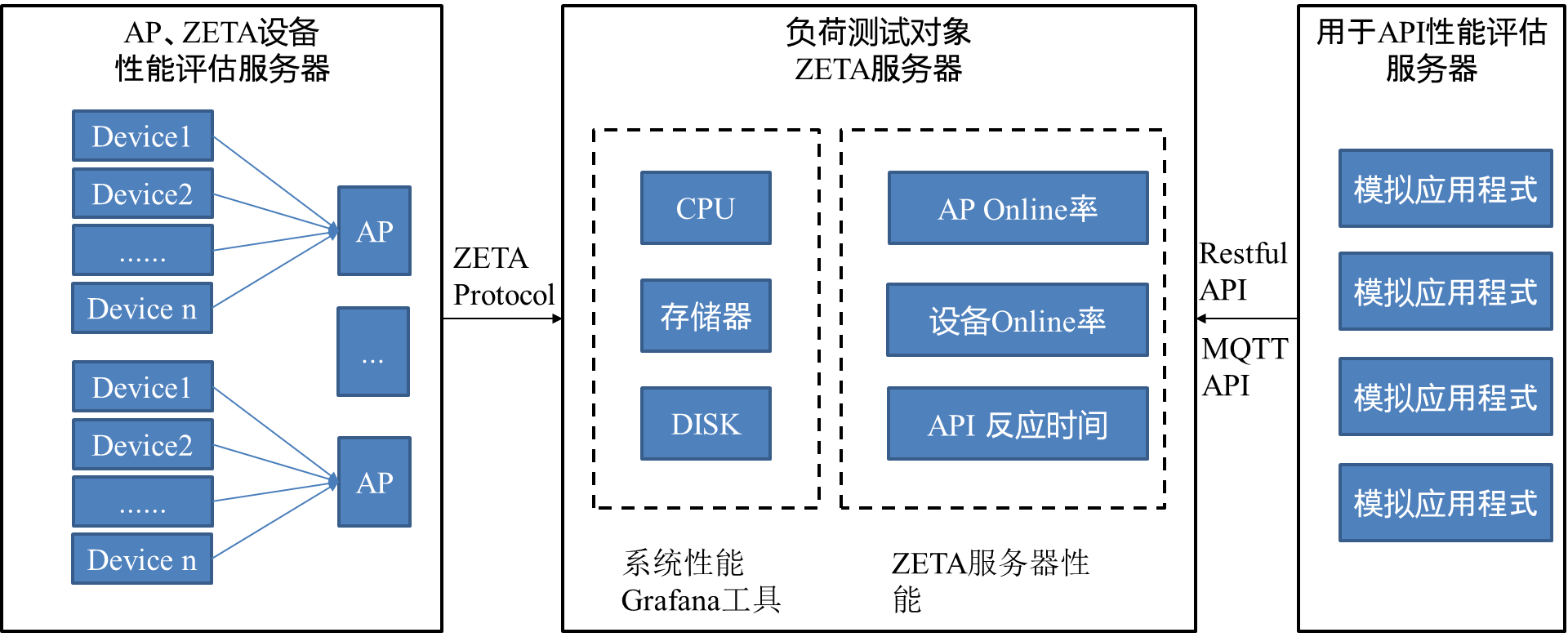
1500万 Zetag标签压测
zetag压测场景描述
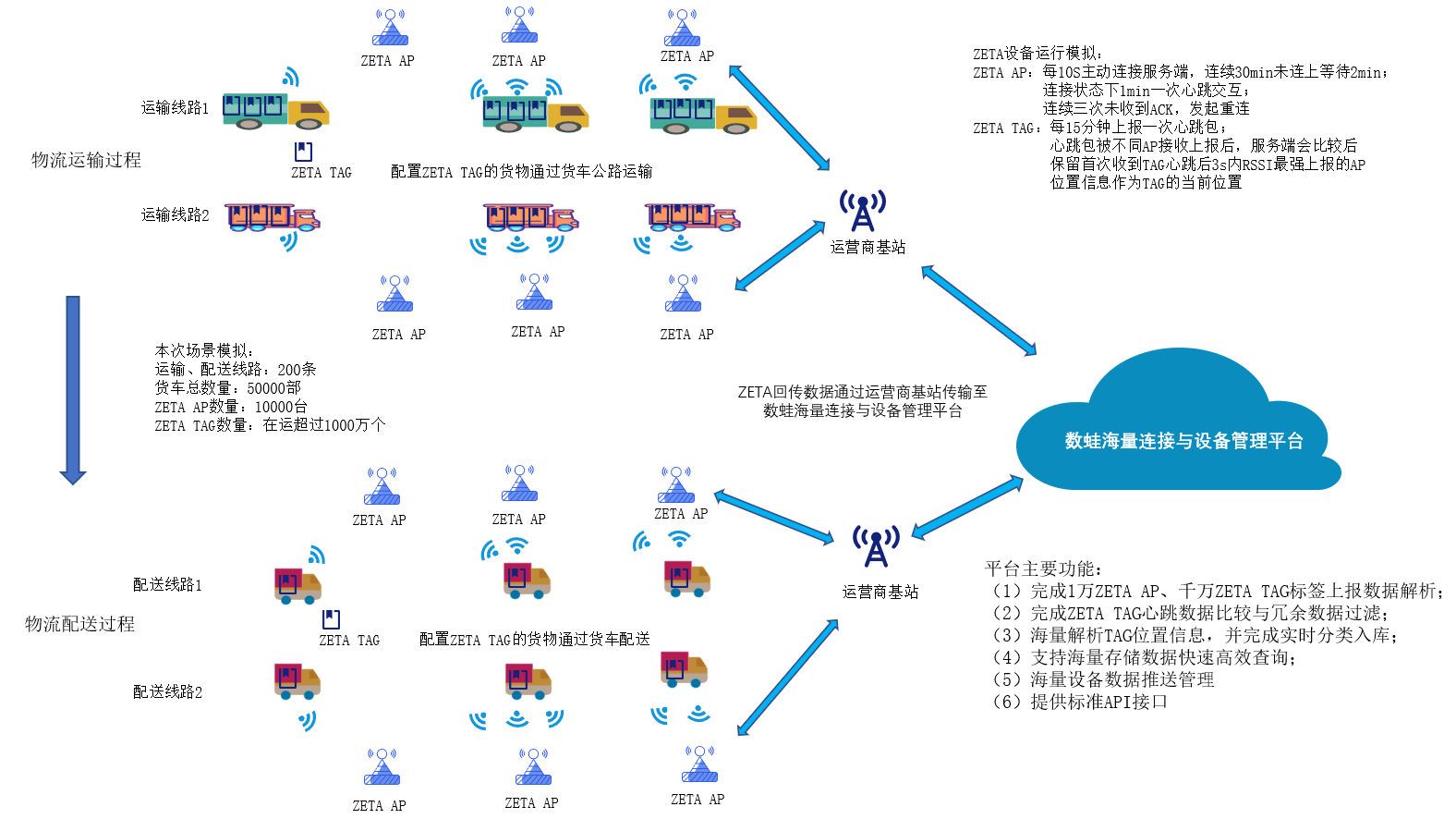
zetag压测网络架构
Zetag压测结果
| 测试结果 | 测试内容 | 测试结果 |
|---|---|---|
| 10000 | 请求次数/次 | 200000 |
| 100% | 测试总时间/秒 | 269.583 |
| 最大值:17171432 | 请求返回200数 | 120116 / 200000 |
| 合计:10324032 | 请求返回404数 | 79884 / 200000 |
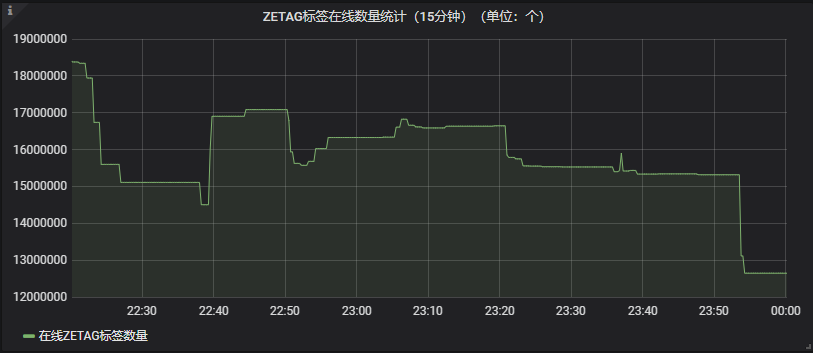
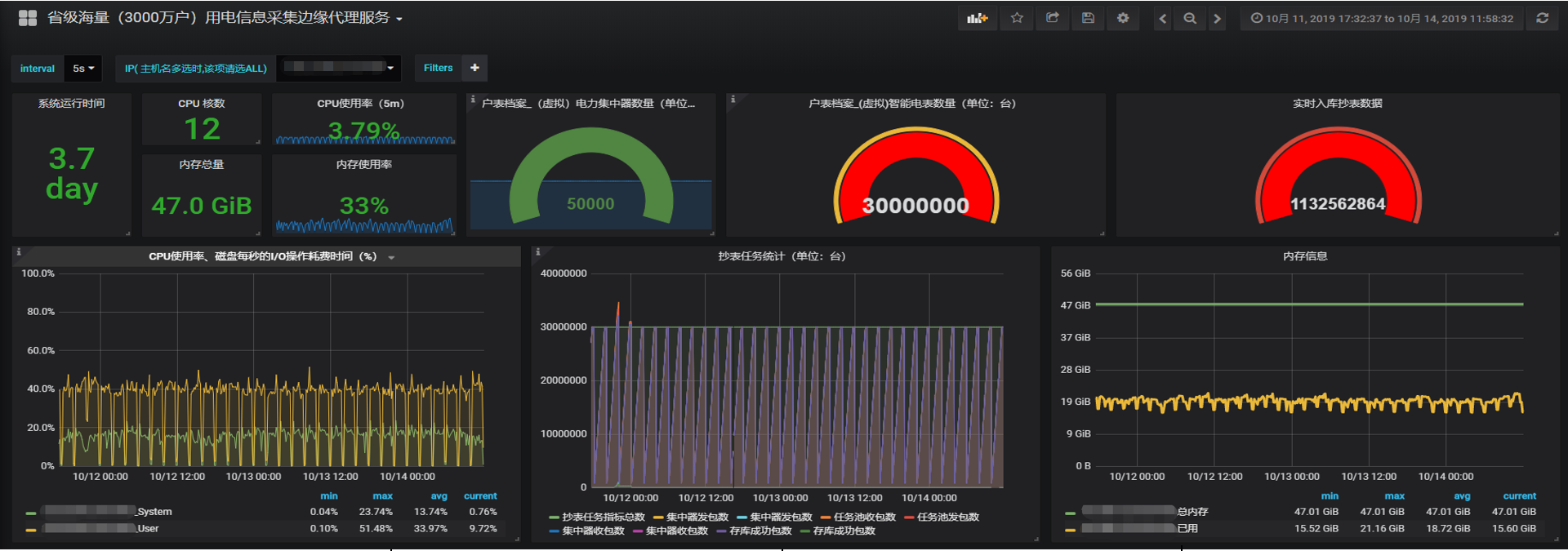
3000万 电表集抄压测
报告系统
报告系统部署
shuwa_report-4.0.0.zip 点击下载,解压即用
- 支持word文档替换
- 支持主流办公文档的在线预览
linux环境部署
wget http://dgiot-1253666439.cos.ap-shanghai-fsi.myqcloud.com/dgiot_release/shuwa_report-4.0.0.zip && unzip shuwa_report-4.0.0.zip
./shuwa_report-4.0.0/bin/startup.sh
安装完之后可以打开 ip:8012/doc.html swagger接口文档即部署成功
大部分Linux系统上并没有预装中文字体或字体不全,需要把常用字体拷贝到Linux服务器上 运行bin下面的fonts.sh进行安装
./shuwa_report-4.0.0/bin/fonts.sh
基础知识
云压测入门
Promethus
我们知道zabbix在监控界占有不可撼动的地位,功能强大。但是对容器监控显得力不从心。为解决监控容器的问题,引入了prometheus技术。prometheus号称是下一代监控。接下来的文章打算围绕prometheus做一个系列的介绍,顺便帮自己理清知识点。 prometheus是由谷歌研发的一款开源的监控软件,目前已经被云计算本地基金会托管,是继k8s托管的第二个项目。 prometheus根据配置定时去拉取各个节点的数据,默认使用的拉取方式是pull,也可以使用pushgateway提供的push方式获取各个监控节点的数据。将获取到的数据存入TSDB,一款时序型数据库。此时prometheus已经获取到了监控数据,可以使用内置的PromQL进行查询。它的报警功能使用Alertmanager提供,Alertmanager是prometheus的告警管理和发送报警的一个组件。prometheus原生的图标功能过于简单,可将prometheus数据接入grafana,由grafana进行统一管理。
Promethus监控的目的
google指出,监控分为白盒监控和黑盒监控之分。
白盒监控:通过监控内部的运行状态及指标判断可能会发生的问题,从而做出预判或对其进行优化。
黑盒监控:监控系统或服务,在发生异常时做出相应措施。
监控的目的如下:
根据历史监控数据,对为了做出预测
. 发生异常时,即使报警,或做出相应措施
根据监控报警及时定位问题根源
. 通过可视化图表展示,便于直观获取信息
Promethus常用概念
prometheus采集到的监控数据均以metric(指标)形式保存在时序数据库中(TSDB) 每一条时间序列由 metric 和 labels 组成,每条时间序列按照时间的先后顺序存储它的样本值。 默认情况下各监控client向外暴露一个HTTP服务,prometheus会通过pull方式获取client的数据,数据格式如下:
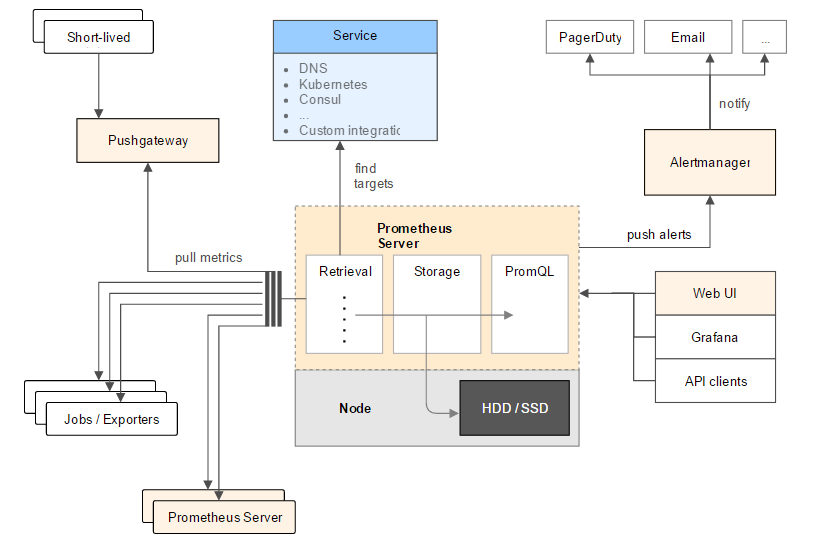
# HELP node_cpu Seconds the cpus spent in each mode.
# TYPE node_cpu counter
node_cpu{cpu="cpu0",mode="idle"} 362812.7890625
# HELP node_load1 1m load average.
# TYPE node_load1 gauge
node_load1 3.0703125
以#开头的表示注释信息,解释了每一个指标的监控目的和类型
node_cpu表示监控指标的名称
{}内的内容是标签,以键值对的方式记录
数字是这个指标监控的数据
下图横坐标代表的是时间(时间戳的方式记录在TSDB中),纵坐标代表了各种不同的指标名称,坐标系中的黑点代表了各个指标在不同时间下的值。
每一个横线 就是时间序列
每个黑点就是样本(prometheus将样本以时间序列的方式保存在内存中,然后定时保存到硬盘上) 指标(metric)的格式如下:
<metric name>{<label name>=<label value>, ...}
指标名称反映的是监控了什么。 标签反映的是样本的维度,可以理解成指标的细化。比如:
api_http_requests_total{method="POST", handler="/messages"}
指标是“api_http_requests_total”,含义是通过api请求的http总数。 标签“method="POST"” "handler="/messages""代表了这些http请求中 POST 请求 并且 handler是/messages的数量 上述指标等同于:
{__name__="api_http_requests_total",method="POST", handler="/messages"}
Promethus指标有四种类型
1. Counter 只增不减 计数器
2. Gauge 可增可减 仪表盘
3. Histogram 直方图
4. Summary 摘要型
Promethus任务与实例
就Prometheus而言,pull拉取采样点的端点服务称之为instance,通常对应一个过程(实例)。具有相同目的的instance,例如,为可伸缩性或可靠性而复制的流程称为作业。, 则构成了一个job
例如, 一个被称作api-server的任务有四个相同的实例。
job: api-server
instance 1:1.2.3.4:5670
instance 2:1.2.3.4:5671
instance 3:5.6.7.8:5670
instance 4:5.6.7.8:5671
自动化生成的标签和时间序列 当Prometheus拉取一个目标,会自动地把两个标签添加到度量名称的标签列表中,分别是:
job: 目标所属的配置任务名称。
instance: 被抓取的目标网址的一部分务: host:port
如果以上两个标签二者之一存在于采样点中,这个取决于honor_labels配置选项。详见文档
对于每个采样点所在服务instance,Prometheus都会存储以下的度量指标采样点:
up{job="[job-name]", instance="instance-id"}: 1:表示采样点所在服务健康; 0:标识抓取失败
scrape_duration_seconds{job="[job-name]", instance="[instance-id]"}: 抓取的持续时间
scrape_samples_post_metric_relabeling{job="<job-name>", instance="<instance-id>"}: 应用度量标准重新标记后剩余的样本数。
scrape_samples_scraped{job="<job-name>", instance="<instance-id>"}: 目标暴露的样本数量 up度量指标对服务健康的监控是非常有用的。
Promethus名词解释
| 模块 | 名词 | 描述 |
|---|---|---|
| Prometheus | Alert | 一条Alert是Prometheus一条警报规则的输出(处于着火状态的警报输出)。一条Alert产生后,由Prometheus发送给Alertmanager。 |
| Prometheus | Alertmanager | Alertmanager接收Alerts,将它们聚合成组、去重,应用沉默、节流,然后发送通知到邮件, Pagerduty, Slack等。 |
| Prometheus | Bridge | Bridge是一个组件,它从Client library采样,同时把这些数据暴露给一个非Prometheus的监控系统。比如:可以把Python, Go, and Java客户端的metrics暴露给Graphite。 |
| Prometheus | Client library | Client library是一个用某种语言(比如:Go, Java, Python, Ruby等)写的库。Client library可以直接在你的代码中使用;可以写一个定制化的收集器,从其它系统pull metrics,同时暴露这些metrics给Prometheus。 |
| Prometheus | Collector | Collector是Exporter的一部分,它代表一组metrics。It may be a single metric if it is part of direct instrumentation, or many metrics if it is pulling metrics from another system |
| Prometheus | Direct instrumentation | Direct instrumentation is instrumentation added inline as part the source code of a program. |
| Prometheus | Endpoint | 一个能够被抓取metrics的源,通常相当于一个进程。 |
| Prometheus | Exporter | Exporter是一个给Prometheus暴露metrics的二进制程序,用于把非Prometheus格式的metrics转为Prometheus格式的metrics。 |
| Prometheus | Endpoint | 一个能够被抓取metrics的源,通常相当于一个进程。 |
| Prometheus | Instance | Instance是一个标识job中target的一个标签。 |
| Prometheus | Job | 一组有相同目的的目标,叫做作业。比如监控一组用于高可用和可伸缩的进程。 |
| Prometheus | Notification | Notification代表由一个或多个alerts组成的警报组。Alertmanager发送Notification给邮件, Pagerduty, Slack等。 |
| Prometheus | Promdash | Promdash是Prometheus自带的dashboard。生产上建议使用Grafana。 |
| Prometheus | Prometheus | Prometheus一般是指Prometheus系统的核心二进制文件。有时也指Prometheus监控系统本身。 |
| Prometheus | PromQL | PromQL是Prometheus查询语言。它支持aggregation, slicing and dicing, prediction and joins。 |
| Prometheus | Pushgateway | The Pushgateway会保存批量任务最近push的metrics。Prometheus能够从Pushgateway抓取这些metrics。 |
| Prometheus | Remote Read | Remote Read是Prometheus提供的一个功能,它支持Prometheus从其它的系统(长期存储系统)读取时间序列数据(作为查询的一部分)。 |
| Prometheus | Remote Read Adapter | 不是所有的系统原生的支持远端读操作。Remote Read Adapter位于远端系统和Prometheus之间,转换时间序列请求和响应。 |
| Prometheus | Remote Read Endpoint | Remote Read Endpoint是远端系统的endpoint,Prometheus与这个endpoint通信。 |
| Prometheus | Remote Write | Remote Write是Prometheus提供的功能,它支持把收集到的metrics远程写入到远端系统(长期存储系统)。 |
| Prometheus | Remote Write Adapter | 不是所有的系统都原生支持Prometheus远程写操作。Remote Write Adapter是一个适配器,位于Prometheus与远端系统之间,把Prometheus的metrics转化为远端系统能够理解的数据格式。 |
| Prometheus | Remote Write Endpoint | A remote write endpoint is what Prometheus talks to when doing a remote write。 |
| Prometheus | Silence | Silence是Alertmanager提供的功能,用于阻止特定的alerts。这些alerts的标签与Silence设定的标签相匹配。 |
| Prometheus | Target | A target is the definition of an object to scrape. For example, what labels to apply, any authentication required to connect, or other information that defines how the scrape will occur。 |
Grafana名词解释
| 模块 | 名词 | 描述 |
|---|---|---|
| Grafana | DataSource | Grafana支持许多不同的时间序列数据(数据源)存储后端。每个数据源都有一个特定的查询编辑器。官方支持以下数据源:Graphite、infloxdb、opensdb、prometheus、elasticsearch、cloudwatch。每个数据源的查询语言和功能明显不同。您可以将来自多个数据源的数据组合到一个仪表板上,但每个面板都要绑定到属于特定组织的特定数据源。 |
| Grafana | Organization | grafana支持多个组织,以支持各种部署模型,包括使用单个grafana实例为多个可能不受信任的组织提供服务。 |
| Grafana | User | 用户是grafana中的命名帐户。用户可以属于一个或多个组织,并且可以通过角色分配不同级别的权限。Grafana支持各种各样的内部和外部方法,供用户进行身份验证。这些包括来自自己的集成数据库、来自外部SQL Server或来自外部LDAP服务器。 |
| Grafana | Row | 行是仪表板中的逻辑分隔符,用于将面板分组在一起。行总是12“单位”宽。这些单位根据浏览器的水平分辨率自动缩放。通过设置面板自身的宽度,可以控制一行中面板的相对宽度。我们使用了一个单元抽象,这样Grafana在无论是小屏幕还是大屏幕 看起来都很舒服。 |
| Grafana | Panel | 面板是Grafana中的基本可视化构建块。每个面板都提供一个查询编辑器(取决于面板中选择的数据源),通过使用查询编辑器,您可以提取显示在面板上的完美可视化效果。有各种各样的样式和格式选项,每个面板开源,让您创建完美的图片。面板可以在仪表板上拖放和重新排列。它们也可以调整大小。当前有四种面板类型:graph、singlestat、dashlist、table和text。 |
| Grafana | Query Editor | 查询编辑器公开数据源的功能,并允许您查询它包含的度量。使用查询编辑器在时间序列数据库中生成一个或多个查询(针对一个或多个序列)。该面板将立即更新,允许您实时有效地探索数据,并为该特定面板构建一个完美的查询。您可以在查询本身的查询编辑器中使用模板变量。这提供了一种基于仪表板上选择的模板变量动态探索数据的强大方法。Grafana允许您在查询编辑器中按查询所在的行引用查询。如果向图形中添加第二个查询,只需键入a即可引用第一个查询。这为构建复合查询提供了一种简单方便的方法。 |
| Grafana | Dashboard | 仪表盘就是一切的归宿。仪表板可以看作是一组组织并排列成一行或多行的一个或多个面板。仪表板的时间段可以由仪表板右上角的仪表板时间选择器控制。仪表盘可以利用模板化使其更具动态性和互动性。仪表板可以利用注释在面板之间显示事件数据。这有助于将面板中的时间序列数据与其他事件关联起来。仪表板(或特定面板)可以通过多种方式轻松共享。您可以向登录您的Grafana的人发送链接。您可以使用快照功能将当前查看的所有数据编码为静态和交互式JSON文档;这比通过电子邮件发送屏幕截图要好得多!可以标记仪表板,仪表板选择器提供对特定组织中所有仪表板的快速、可搜索访问。 |
DGTEST名词解释
| 模块 | 名词 | 描述 |
|---|---|---|
| DGTEST | Task | dgiot开发的面向工业物联网的高并发模拟压测程序,有完整的业务流程。 |
| DGTEST | Report | 用户最终得到的word压测报告文件,包含压测的业务场景、压测过程数据与图表。 |
| DGTEST | Report Label | 统计指标或者图标与word报告中标签关系,job_metrics 例如,job为zeta_server,metrics为CPU_max,则实际标签为zeta_server_CPU_max,通过统计标签与word文件动态映射数据 |
| DGTEST | Report templates | 用户根据业务需求定制的word模板后,把需要动态替换的图片或者文件替换成DGTEST_LAB后形成的模板文件。 |
压测相关压测api
| 名称 | 地址 | 说明 |
|---|---|---|
| 查询所有job | http://ip:9090/api/v1/targets | 新建任务使用 对应各类exporter |
| 查询对应job所有统计指标 | http://ip:9090/api/v1/targets/metadata?match_target={job=%22zeta_metrics%22} | 新建任务后li使用 |
| 查询所有面板 | http://ip:3000/api/search | 图片服务器使用 |
| 查询统计图片 | http://ip:3000/api/dashboards/uid/9CWBz0bik | 与面板指标关联 |
生态api
| 名称 | 地址 | 说明 |
|---|---|---|
| grafana api | https://grafana.com/docs/ | http://ip:3000/ |
| prometheus api | https://prometheus.io/docs/prometheus/latest/querying/api/#tsdb-admin-apis | http://ip:9090/graph |
| word api | http://deepoove.com/poi-tl/#_why_poi_tl | http://ip:8085/report/doc.html |
操作指南
整体流程
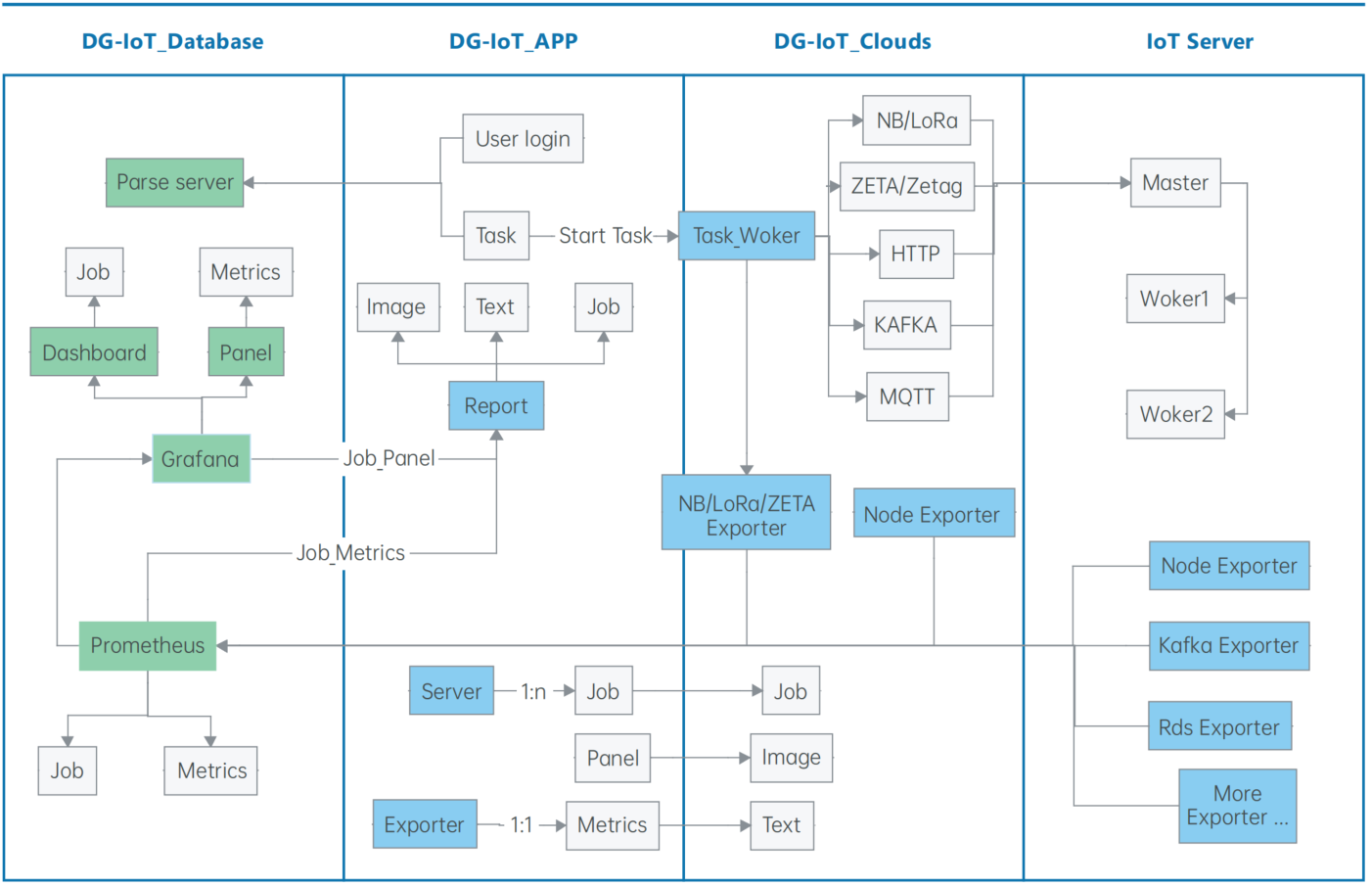
如上图,四个exporter自身会产生类似于发包数的统计值metrics。然后task_work这个任务以时间顺序将统计值暴露。promethues以一定的时间间隔去读取该统计值,存储为时序数据。Grafana从promethues得到job和metrics数据,并分别以仪表盘(dashboard)与面板(penel)的形式展示。生成报告时,report系统从grafana中以“Job_Legend”和“Job_Panel”形式将值提取出来,形成特定格式的json文件,模板传参分别替换报告模板中的指定文本和图片占位符,生成报告。
1. 在Prometheus内添加job
添加新的job
cd /data/prometheus-2.9.2.linux-amd64/
vim prometheus.yml
按i键进入编辑模式,增加一个job,例如ry-worker2
- job_name: 'ry-worker2'
static_configs:
- targets: ['14.14.19.132:9100']
修改好之后,按ecs键退出编辑模式,输入wq!保存退出,注意
ps aux|grep prometheus
root 14505 0.2 1.2 728164 99764 ? Sl Mar16 28:33 ./prometheus
root 16256 0.0 0.0 112812 976 pts/0 S+ 18:50 0:00 grep --color=auto prometheus
kill -9 14505
nohup ./prometheus &
2. 在grafana添加数据源
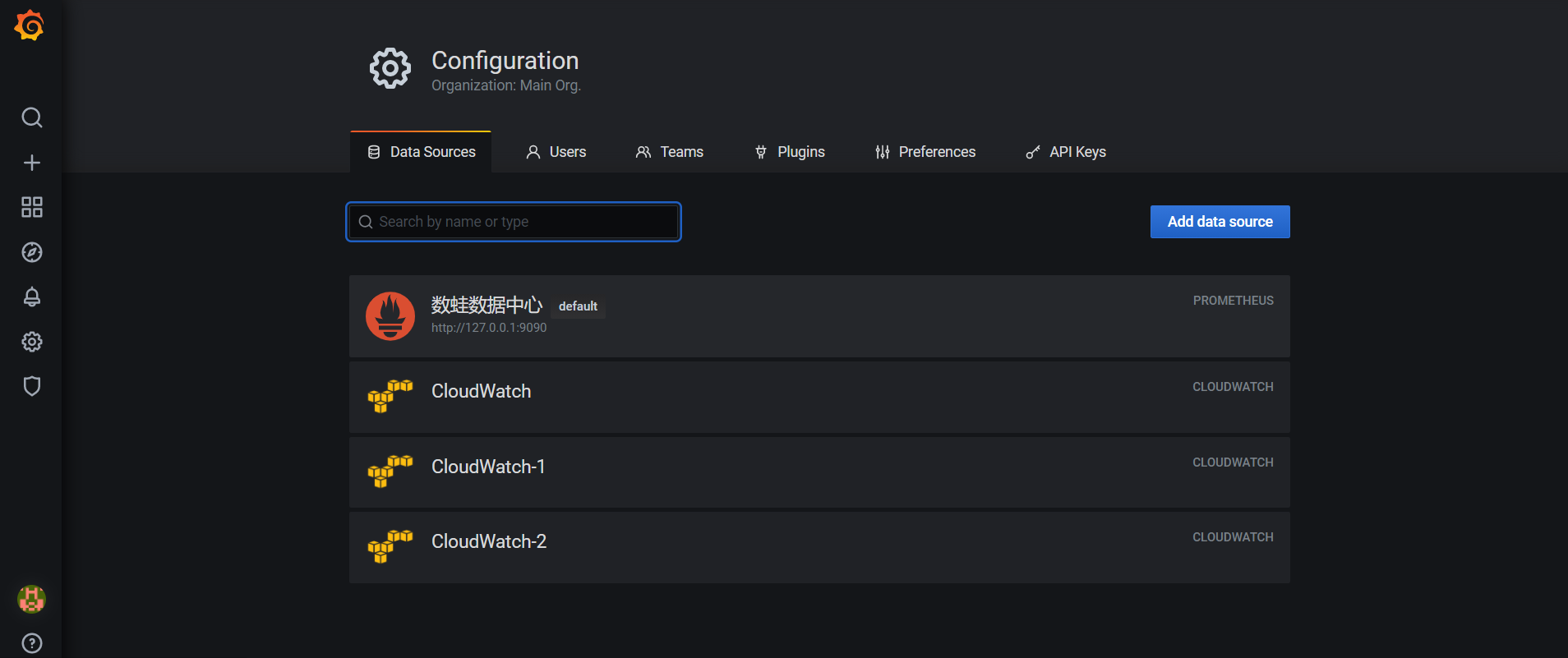
在grafana首页,点击设置图标,再点击Data Sources进入数据源设置界面。我们可以添加选择所需要的数据源,数据源本质是ip和端口值。
3. 查看该数据源下的job和metrics
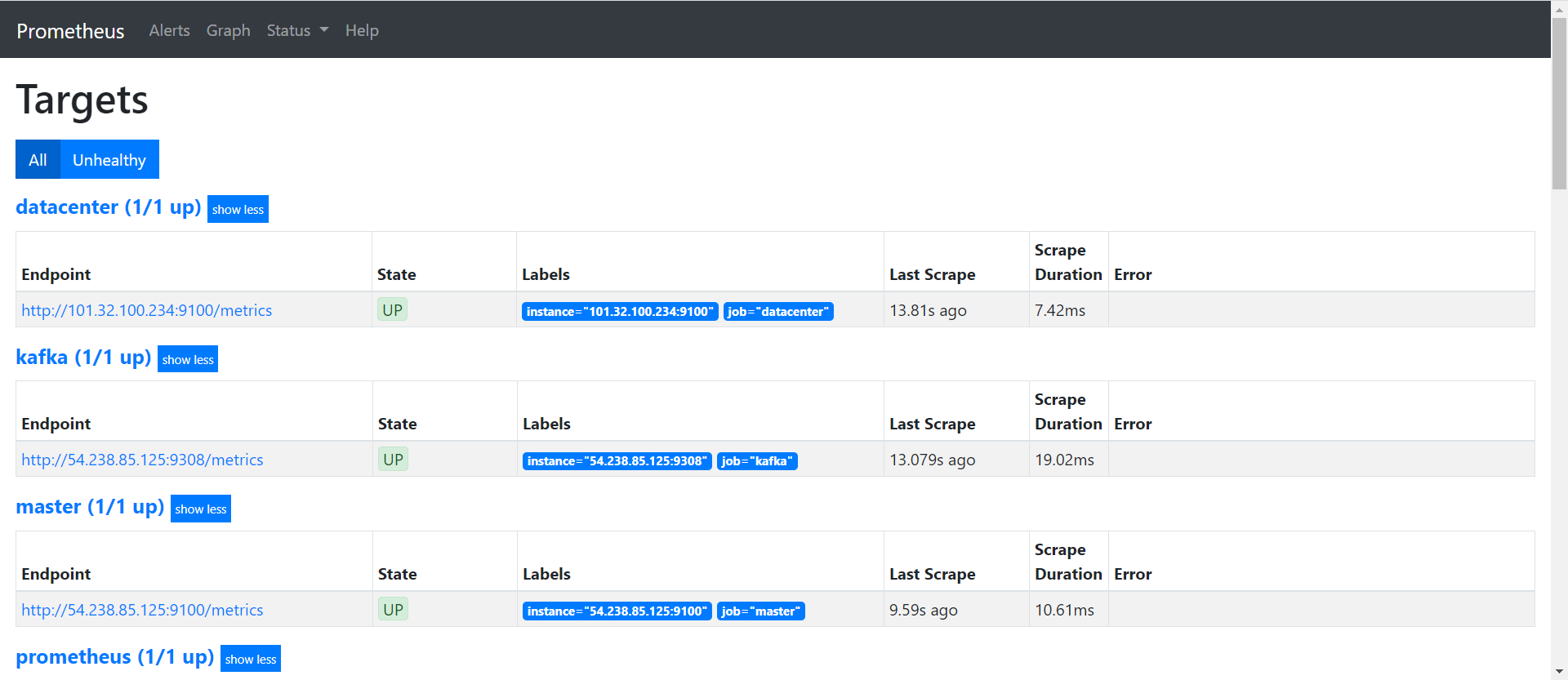
将grafana的端口值改为9090,即可进入promethues界面。点击targets,我们可以看到我们第一步添加成功的job。注意job和Instance值是一一对应的,但job值不会改变,而instance会随着服务器的改变而改变,故我们以job为标签。点击instance对应的ip加端口,得到下面的页面,我们可以看到该job下metrics的查询语句以及值。

4. 在grafana添加Panel
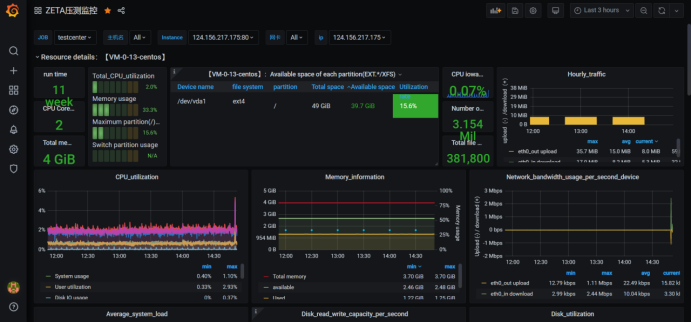
4.1 增删查改面板
grafana里面添加或者减少metrics,需要通过面板(panel)的增删查改来实现。点击页面上方的Add panel即可添加新的面板。一个面板对应一个或者几个有一定联系的metrics。我们在第三步已经得到了job和metrics,接下来通过panel来添加该job下对应的metrics。
也可以通过复制粘贴已有的面板,来获得新的面板。如下图,鼠标放置在标题(Panel Title)区域,点击向下的箭头,再在more选项里选择copy即可复制已有面板。
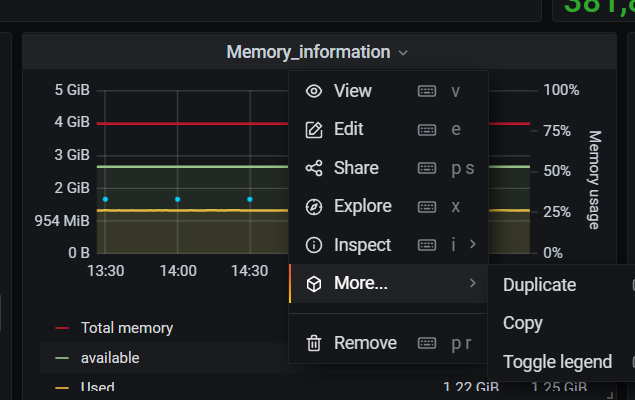
创建新的面板后,便是修改其配置了。通过点击上图的Edit按钮,进入面板编辑页面。
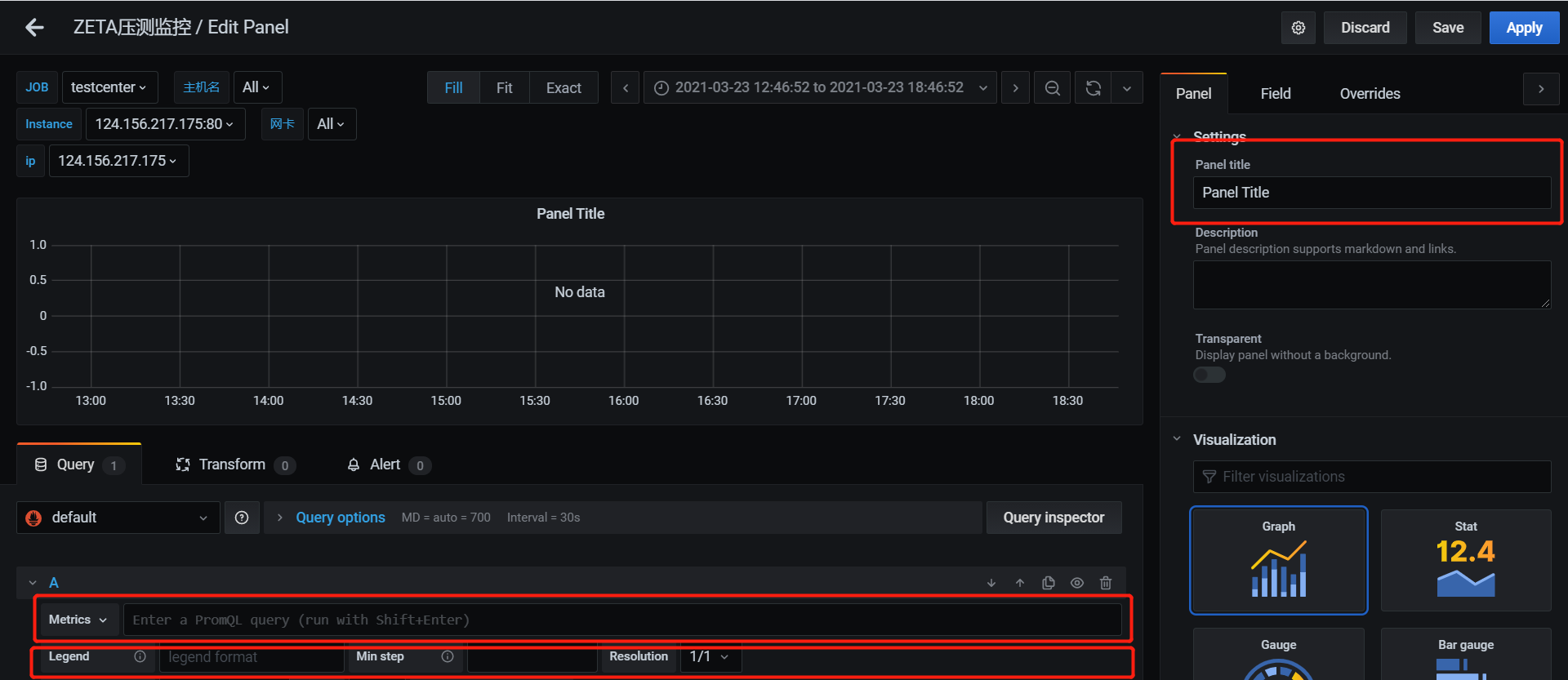
面板一般有三个参数需要设置:
| 参数 | 含义 | 举例 | 备注 |
|---|---|---|---|
| Panel Title | 面板标题 | Memory_information | 英语,单词间用下划线连接 |
| Metrics | 指标 | node_memory_MemTotal_bytes{instance=~"$node"} | 在第3步中得到 |
| Legend | 指标名 | Total memory | |
| 与面板相似,Query板块也可以进行增删改查,划到Query板块最下方区域,点击加号即可增加新的指标。 | |||
| 注意:以上设置在修改后,要点击保存,以免丢失进度! |
4.2 对metrics进行计算
有时候我们不仅仅需要系统已有的metrics值,还需要对其进行一定的计算,比如取整或保留2位有效小数。我们可以在Query板块增加一个新的指标栏。在metrics对应的空,按规则写入查询语句。在legeng对应的空给其取名。
举例:
以下是runtime的meteics语句,用以表示运行时长,单位是秒。
```
avg(time() - node_boot_time_seconds{instance=~"$node"})
```
但我们想要以天为单位,这个时候就需要对其进行计算。我们另取名runtime1表示以天为单位的运行时长。注意,后面生成报告取值时,要选择runtime1,而不是runtime。runtime1的metrics语句如下:
round(avg(time() - node_boot_time_seconds{instance=~"$node"})/24/60/60, 0.01)
4.3 grafana各参数内部关系
grafana重要的几个概念是:job,panel和metrics,legend。通过上述操作流程,我们其实可以看出,一个job通过增删查改拥有多个panel,一个panel通过增删查改拥有多个metrics,一个metrics对应一个legend。但是,每一个job里面的panel不能重复,每一个panel里面的metrics不能重复。即参数命名方式“JOB_Legend”是唯一确定的变量。如“master_memory_min”表示的是master服务器的memory_min这个变量,不会产生歧义。
####5. 在压测平台中修改报告配置
在网站首页,点击任务报告,进入报告配置界面。
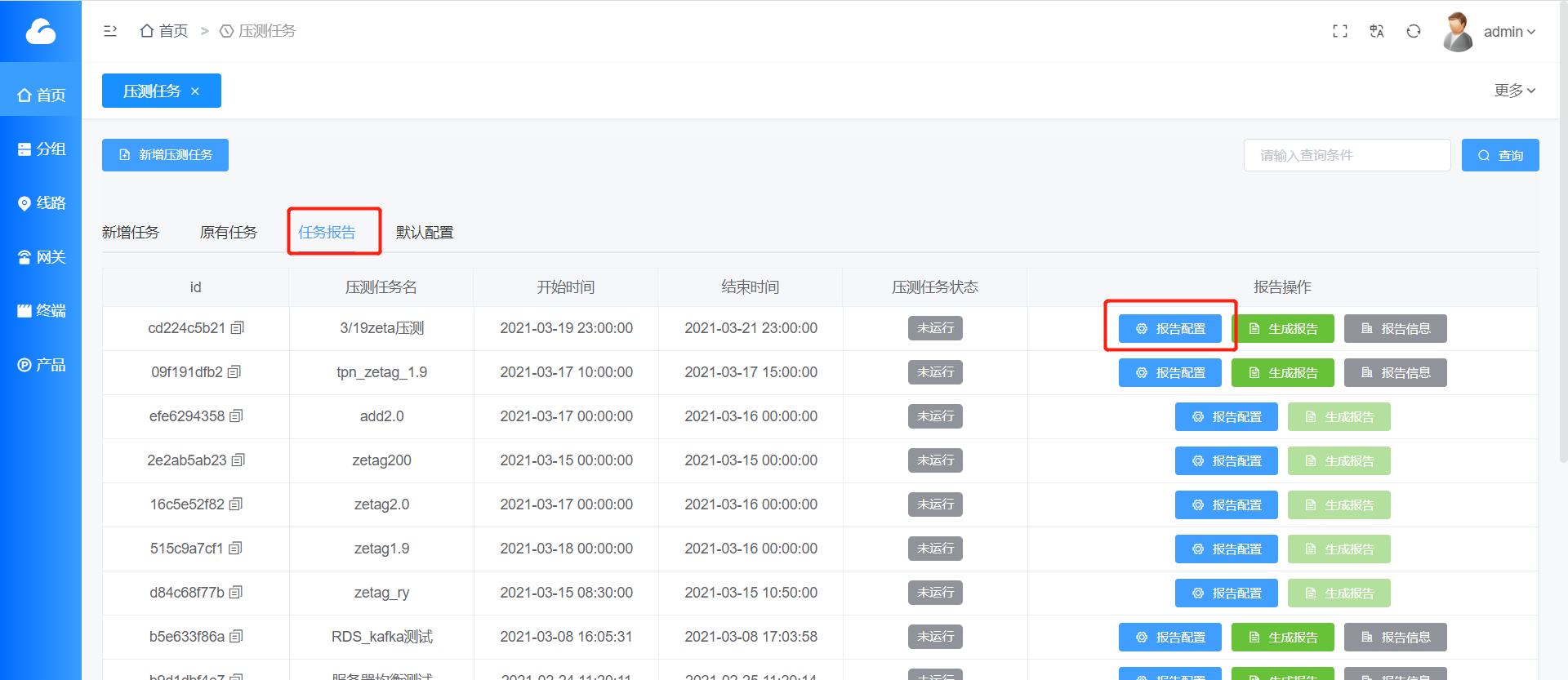
点击报告配置,进入配置信息页面,有新增、扫描和保存配置按钮。
新增按钮可以添加grafana不包含的配置信息,如说明性信息。
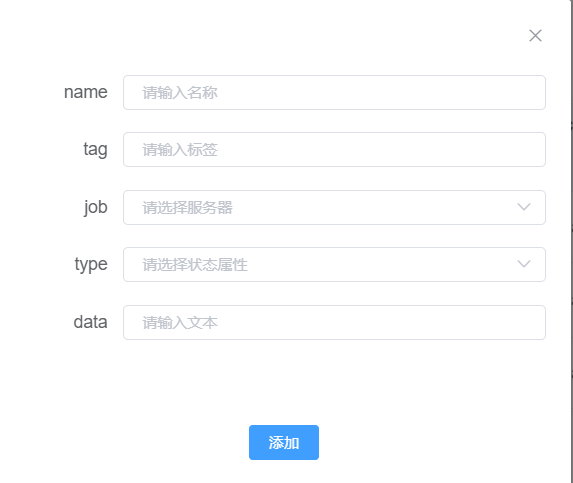
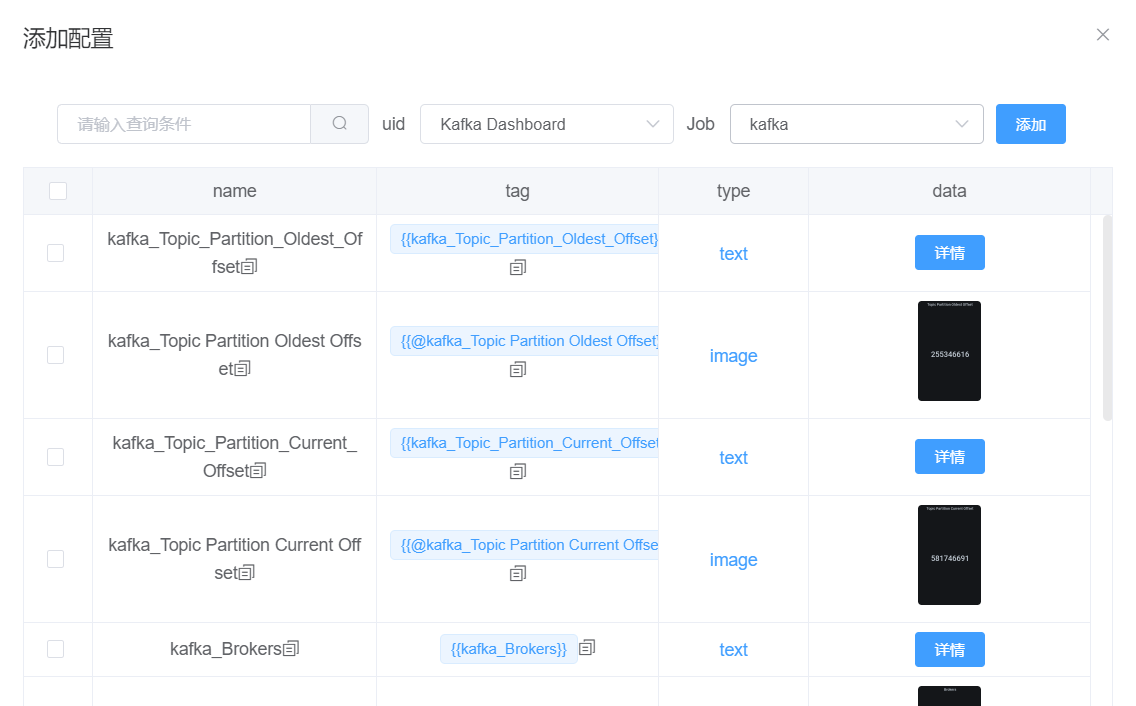
扫描按钮可以获得grafana里面包含的所有配置信息。如下图,uid选择不同的仪表盘;job是选择服务器;而搜索框可以输入查询条件,提高查询速度与精度。 我们添加配置时,要先确定我们需要的数据是哪个仪表盘的,通过uid选择确定。然后,确定这一份报告需要用哪几个服务器的数据。 注意,一份报告的数据可能会对应多个服务器。在job里选择需要的服务器,即可得到该仪表盘、该服务器下的所有配置信息。 点击命名方式为“JOB_Legend”的配置信息,可以同时添加多个,点添加按钮即可添加成功。 接下来,通过job选择需要的其他服务器,反复上述操作,直到所需配置信息全部配置成功。 最后,点击添加按钮。
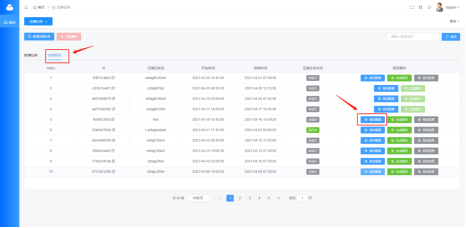
现版本报告配置流程如下:
1.点击进入报告配置页面,点击“扫描”。
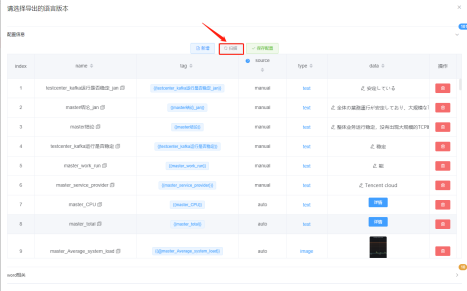
2.选择对应指标:(以ZETA負荷試験監視面板里job:master的CPU核数为例)
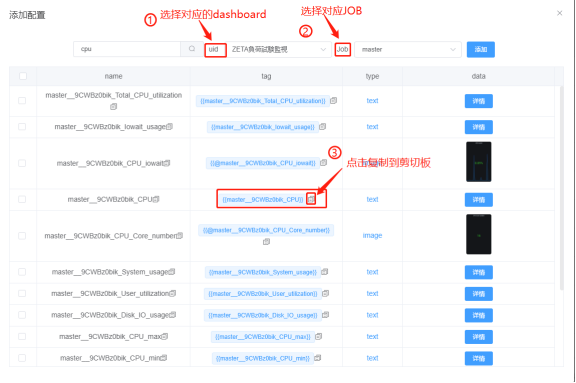
注:对应的grafana的情况如下:

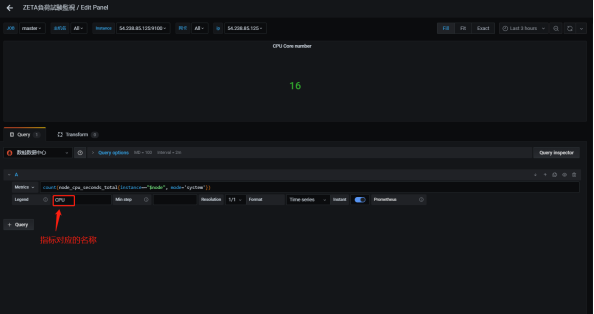
3.在报告模板(word)中粘贴上一步中复制的指标:
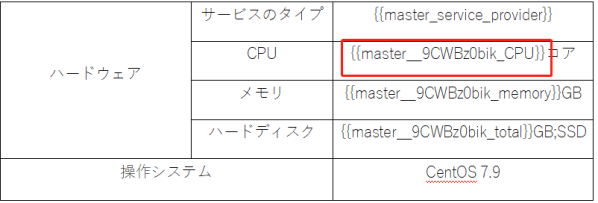
功能讲解: 1.与原版本主要不同在于不需要扫描后选择指标后添加到网页(配置信息)中,只需配置word模板。(新增功能操作同以前) 2.原tag格式例为:{{master_CPU}}
现tag格式例为:{{master__9CWBz0bik_CPU}}
即{{JOB名称_对应dashboard的uid指标名称}}
(注:建议按上述说明直接从页面复制指标tag)
(注:如指标无对应job,可随意选择job,一定要选对dashboard)
上例中job名称是master,dashboard是ZETA負荷試験監視,对应的uid为9CWBz0bik,指标名称为CPU。(对应的job和dashboard可从grafana得知) 3.现版本更新服务器地址或创建新任务等操作时,不需要重新配置指标,只需确保使用的word里的指标能对应目标中的指标。
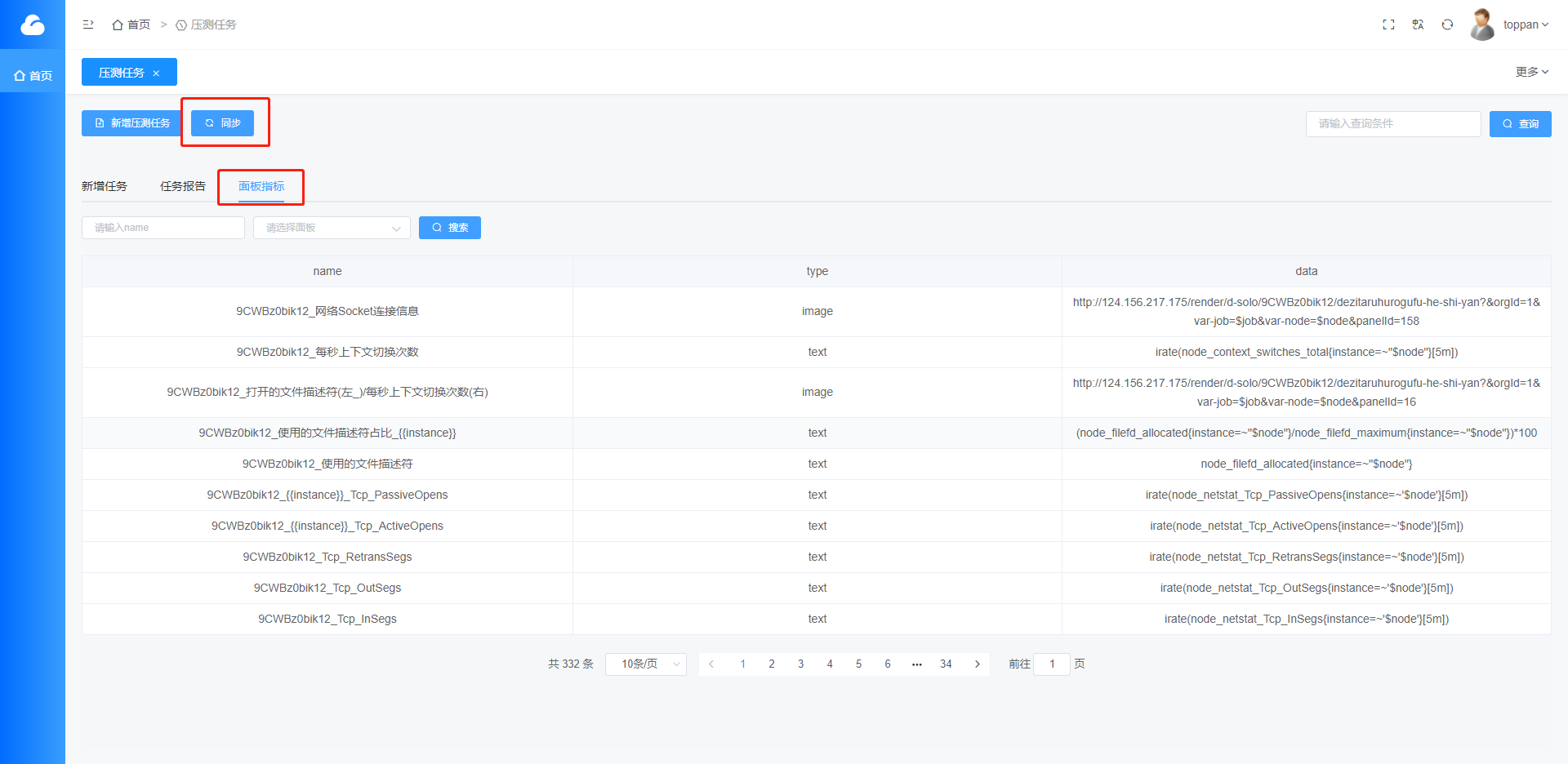
4.新增同步按钮和面板指标页面,可以查看所有面板的指标,根据面板查询该面板指标,每次添加修改grafana里的面板指标,必须同步该面板指标
name:dashboard的uid_指标名称
type: 类型
data:表达式
常见问题
问:如何解决某个时间段内取最值?
答:取一个时间段内的最值时,需要用到
max(min)_over_time语句。例如,想要知道一段时间内的mqtt上线数最大值时,metrics如下:
max_over_time(mqtt_online{instance=~'$node'}[5h:])
其中,[5h:]表示往前推5个小时,将其放在max_over_time()的括号里面。
问:添加新的
exporter时,需要重新配置panel吗?答:需要的。与添加上一个
exporter的操作一模一样。
- 问:报告模板里面的占位符与
grafana有什么关系?
答:首先,我们需要知道报告模板的占位符有哪些书写格式。不同格式占位符都替换哪些文件样式。
| 书写格式 | 替换样式 |
|---|---|
"{ {"+"job_legend"+"} }" | 文本 |
"{ {"+"@"+"job_panel_title"+"} }" | 图片 |
如上表,占位符{ { job_legend } }将job下的legend的值替换报告模板的文本位置。占位符{ { job_panel_title } }将job下的panel图替换报告模板的图片位置。 |
问:当修改了一个
job的某些配置,比如metrices与legend,是否还需要修改其他job的相应配置?答:不需要。不同
job的配置是同步的,修改了某个job的某些配置,其他job相应配置也会自动改变。